
Leveraging Azure Queue Storage and Power Automate for smart Power BI dataset refreshes
- Ben Watt

- Apr 10, 2023
- 3 min read
Updated: Apr 12, 2023
I use Power Automate to trigger Power BI dataset refreshes when files arrive in a source folder (like SharePoint Document library or Azure Data Lake Storage). In one scenario I had a dataset loading/combining files from multiple folders into separate tables. The files would land in the various folders at certain times of the day, often at once and in multiples.

The issue I was facing was the Power Automate Flow would be triggered multiple times so I'd get failures that the dataset was already running on the second & subsequent runs. Basically the multiple Flow executions were running in parallel and tripping over each other. Adding to that, it was a full dataset refresh each time.
Let's fix this...
The main concept was to switch the activities of "new file(s) have dropped" and "let's process" from being synchronous to asynchronous. I created a middle ground to store information as to what files have landed and then a separate process to read this data and perform an efficient dataset process.
In my case, I used Azure Queue Storage as my message service. Queue Storage is an enterprise message storing & processing service. It's actually made for much larger scale solutions, but I've been wanting to use it for a while. You could easily replace it with a simpler thing like Excel or SQL.
The process creates a message every time a file is added/edited. On a scheduled basis the messages are read and it performs a refresh using the Refresh Dataset in Group REST API. In the request body, I include the list of tables that needed processing for a more efficient overall solution.
Here's the breakdown
Create the message
I have Power Automate triggers on the source folders when a file is created or updated.
The Flow will be aware which folder was updated and drop a message in the Queue. The message would be in json format like this:
{ "table":"Sales Orders" }This format matches what is needed in the request body of the Refresh Dataset API.
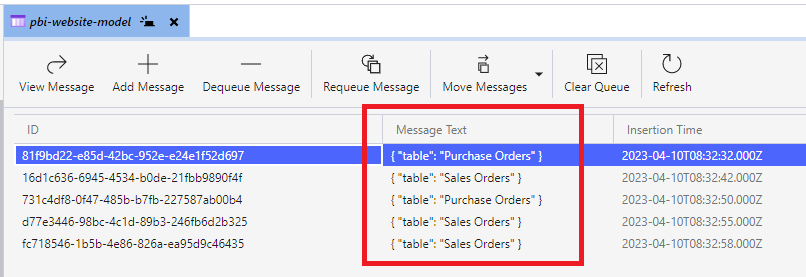
If multiple files are dropped into the same folder then the table will be repeated in multiple messages, but we handle that later. This screenshot shows that the Sales Orders and Purchase Orders tables have been flagged for processing.
Process the messages
On a scheduled basis a Power Automate Flow reads messages from the Queue. If messages are found it adds them to an array variable. Based on the above screenshot of the message queue, the array would look like this

In a Compose step, I generate the correct json body to pass to the Power BI REST API. To handle any repeated messages of the same table, I use the union expression, passing the array variable in twice which removes duplicates. Niiiice!

and the output looks like this

With the json body ready, then it's a simple call to the REST API using the HTTP action.

After that, the messages are removed from the queue using the Delete Messages action.
Empty Queue?
If the Flow is scheduled every hour, there will be many times the queue contains no messages. In this case we don't want to process the dataset. I used a Condition action which checks the length of the queue, and if no messages were found (meaning no source files has been added/edited) it would use the Terminate action and the Flow would basically stop there.

Authentication
I'm connecting to the Azure Storage Queue using Azure AD, as opposed to the account/key. To connect using Azure AD, you must grant the Role of Storage Queue Data Contributor.
Considerations and Limitations
Flow can only read a maximum of 32 messages at a time. If you are hitting this limit, then you'll need to implement a loop process until you've read all messages.
Moving from synchronous to asynchronous using this method means your dataset will only be processed when the next schedule runs. You will lose a bit of that "instant" refresh of your dataset.
The Azure Queue and HTTP actions in Power Automate require the licenced version. You can't do this on the free version you get with Microsoft 365.



Comments